Inform, from the Latin informare: to give form to the mind.
-atics: use technology to do it quickly and automatically.
Informatics: use technology to distribute accurate information to the brains of decision makers, quickly and automatically.
I decided to name my company LD Informatics, or just LDI. Why did I do that? What a weird name… What a weird guy… I know.
Before the company, informatics was a term, loosely defined, that had been bouncing around in my brain for the past few years. It is a blurry picture of an overarching philosophy I have about data in business, which connects my various obsessions—domain-driven data modelling, software engineering, Bayesian inference, and uncertainty quantification—into a cohesive whole. In my head, these things fall under the umbrella of informatics.
And yes, it sounds nerdy and pretentious and a bit sci-fi, and creates adjacency with super technical fields like bioinformatics and geoinformatics, but give a man his word.
I can learn about a client’s systems, and might think to myself that this company has “good” or “bad” informatics. I think that means the term compresses a bunch of useful concepts together, so maybe it’s worth exploring what I’m talking about.
Key points for the impatient
- Data has no inherent worth. Its value is derived from its role in improving decision quality
- What I’m calling informatics is the discipline of turning data into decision-grade information, automatically, including all the scaffolding that makes that possible
- Decision-grade information might be probabilistic analyses, or just point-estimate metrics, depending on what is being deliberated over and what is at stake
- Informatics integrates systems, logic, uncertainty and technical communication over the vertical stack of data flowing through a business
- Most companies have “leaky” informatics, due to manual handoffs, poorly integrated tooling, and spreadsheet-dominated data workflows
- This makes data work inefficient, for human and AI analysts
- Companies with good informatics will get the most leverage out of agentic AI
The rest of this post features me trying to explain what I mean in more detail.
Data is worthless
Data is abundant, and—robbed of its context—worthless.
Even in its context, without understanding and integrating it into decision making, it is still worthless. You could spend millions on data gathering and fail to use it to make the right call, and your money would have been wasted. Maybe it kept some nerds like me busy for a while, and I’ll take it, but the money was still wasted, the data didn’t ultimately serve your goals.
The data isn’t the point. I don’t actually care about data. That might seem like a weird thing to say, coming from someone who spends all his time buried in it, but it’s true.
I care very much about information. I think that is what we all actually care about. We use information to understand what is going on in a messy and complicated operation, and our understanding of that helps us make better decisions. The value of data is inextricably tied to the quality of decision making it enables.
But isn’t data just information? What’s the difference?
Counting sand grains
Let’s say, for some reason, I’m interested in the average size of sand grains at a local beach. The data is each individual measurement of a sand grain.
How many grains do I measure? How valuable is my data gathering process? Well, the uncertainty reduction I get from each new grain is falling off at a rate of one over the square root of the count of grains I’ve measured so far… and the question of when to stop depends on my goals.1

There is a fact about the true average grain size on that beach—we could spend millions of dollars excavating and measuring every grain, and in 10 years arrive at the precise value to 60 decimal places—but we don’t care enough to do it.2
The data only serves us insofar as it provides the information we need, at the level of confidence we need. Maybe we are world-leading sand aficionados and we’ve been hired by a firm for a large sum of money to demonstrate that the local beach has finer sand grains than the next beach along the coast to attract instagram people, or something. If after 1000 grains we still can’t be sure, we’ll keep measuring grains until we are.
Stupid example? Maybe. But how many business contexts involve questions about information gathering and its value?
When do we stop counting sand grains? How do we know when to stop?
Or, translated to a business context:
What data gathering processes are we paying for?
Are we using them effectively?
And, maybe a useful mental refrain:
Is our data paying rent?
My career experience so far has shown me that the answer is, often, no.
I’m building a company to help other companies do this better, and (in conversations with myself, or others if I have a third glass of wine) I call the endeavour informatics.
Real business problems
Real business problems are far more multifaceted and complex than a research question about beach sand.
The “informatics” of a business might require the integration of hundreds of different data streams, propagated through complex logic, aggregated to the resolution that best serves the decision at hand, and delivered to just the right people at just the right time.
It might require jumping out of the core data system and into highly sophisticated software platforms for specialized technical work—but the information that comes out of them should be represented back in the core system, automatically, or your informatics will sprout a leak.
Informatics is the engineering challenge of integrating a vertical stack of data streams—transforming them, analyzing them, visualizing them—all in service of injecting the right information into the right brains at the right time, to hopefully increase the probability of good decisions being made.
Informatics is cloud infrastructure, it’s data engineering, data analysis, data science, it’s business “semantics” and “ontology”, it’s database design and machine learning and Bayesian statistics, it’s pretty plots and dashboards, it’s GIS, it’s risk management. It’s all of those things, deployed in service of that objective: Help a business make better decisions.
Informatics requires a lot of different skills. In an unfamiliar industry, it also requires a lot of ground work in even understanding the shape of the problem. Consultants who don’t understand your business can disguise that reality by calling it semantics or ontology, but that is consultant speak for “we don’t get it, and we’re going to need months of meetings with your people before we can even start”. Maybe I’m wrong, maybe I’m cynical, but that’s what I have observed in my career so far.

I’m starting my informatics career focussed on oil and gas, because I’ve already done most of that groundwork—I know many of these problems back to front, and am packaging solutions in DataBasin—but my goals extend beyond my native industry. Different industries, different problem topologies, same guiding principles.
The information must flow.
Make the data pay rent.
Are we uncertain? Do we care?
When we care
I love Bayesian methods, but I don’t need them to estimate the average grain size on a beach, I’m happy with basic arithmetic.
… But if someone puts a gun to my head, demands an estimate, and only lets me count 20 grains? Well, that changes things.3
Now my uncertainty quantification requirements have gone from, at best, an opportunity to teach something cool about statistics, to a question of life or death.
I know it’s still a dumb example.
My point is that uncertainty is interesting to us insofar as we are exposed to its consequences.
Sometimes, business decisions involve putting hundreds of millions of dollars on the line. If I had to boil down why the oil and gas industry is so interesting to me, it’s that somehow people convince themselves, despite devastating levels of uncertainty, to spend that money, knowing full well there is a good chance it will return no value.
But when you are gambling with a hundred million bucks, your uncertainty about what will happen is, let’s say… of material interest to stakeholders.
So in that context, throw the bloody supercomputer at the problem, pay your best and brightest to do a great job of, ultimately, quantifying the uncertainty, so that decision makers have the right information in their heads when they say “yes” or “no” or “that one, not this one”.
Good decision making under that level of uncertainty requires that information. The sufficient information is not a number, it is a distribution. That is the fit for purpose informatic endpoint for that decision.
Are you going to tell me your managers don’t understand probability distributions? I don’t believe you, but fine. That just means the informatics of the problem includes making distributions understandable to everyone who needs to understand them. That is what good visualizations and good technical communication are for. That is part of informatics.
For example:
Two opportunities cross your desk and you have to pick one.
Option A or Option B?
You choose, business man!
$300m for A, $400m for B.
B is higher. Choose B. Easy money.
Ok, what about now?
Well, there’s some overlap, but we’re still taking B, right? There’s a decent enough chance it is better, so let’s do it!
Ok. And now?
Trickier! And it depends!
But if it’s not clear yet, I can add some visual touches to help:
We don’t want to land left of those lines. You don’t need probability theory to get it.
The uncertainty matters. It doesn’t matter if the manager understands how probability distributions work, it matters that they understand what consequences they are exposed to, given a chosen course of action.
Get the information into the brains that need it to navigate. That’s the objective.
When we don’t care
So I like probability distributions and I’m handy with a Monte Carlo model in a pinch, but when do I not care about them?
Well, production accounting is an example of an uncertainty we tend to ignore, because we just need to agree on canonical numbers—for regulators, for joint venture partners, for our own sanity—not a distribution over them.
Yes, measurements across your production network are imperfect, including the high accuracy fiscal metering at the end of the line. The allocation back to each well or reservoir is absolutely uncertain! How important is that uncertainty? Can we use it? Does information about that uncertainty need to enter a decision maker’s brain to enable them to better navigate?
Maybe in some contexts the answer is yes! Then let’s do it.
Otherwise, just do the accounting. Automate it, so it’s done forever, and the informatics of your metering, your production allocation, your joint venture accounting and production adjacent reporting can be ticked off. Next problem.
Informatics can mean machine learning, it can mean Bayesian statistics, it can mean basic arithmetic. It doesn’t matter. Gather the data flows, get the right information into the right brains, and make it efficient.
This AI agent knows what I’m talking about
I work with AI agents a lot, so I can tell you that they really come alive with this stuff. Software engineers are living in this agent home-turf, every day. For numerical data, databases are their bread and butter.
You can ask Claude pretty much anything about your data and it will hyperactively SQL (squeal) all the answers you are looking for, because it’s fluent. If you’d seen the queries I’ve seen, you’d understand. Trust me.

But the data ontology, Nick!
THINK OF THE ONTOLOGY!!!
A trillion parameters of LLM semantic understanding later, and every offshoot of every subfield of every industry has been ontologically mapped to the point that I can get ChatGPT to sing me a pirate chanty about oil and gas production allocation methodologies, and it won’t shut up:
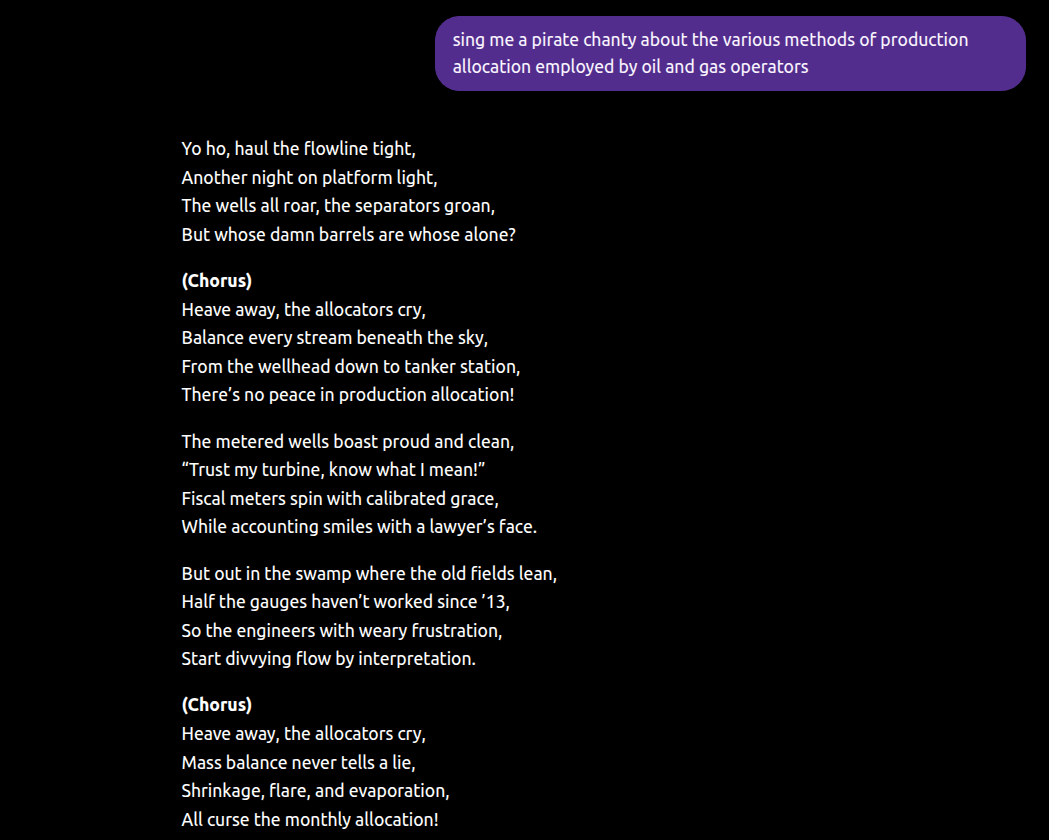
I don’t think ontologies are going to matter much, is my point. If your counterargument is that LLMs are probabilistic and might hallucinate when things are unclear… just make a skill, guys. It’s a markdown file, not months of meetings.
But I digress.
If the information you want is scattered around SharePoint, Claude will have to navigate a GraphAPI full of permissions blockers, hand roll Python scripts on the fly to extract useful data points from PDFs, PowerPoints and spreadsheets, if it can access things, at all. If by some digital Indiana Jones miracle it finally emerges, breathless and defeated, to tell you what a horrible time it had, but here you go, your answer… it got the answer wrong anyway (wrong spreadsheet, the up to date one is on Gary’s laptop).
Agents are going to be incredibly valuable in companies that clean up their informatics, because clean informatics means easily accessible business context, which means reliable AI agent operations. It’s early, but this is the wave that is coming. There is reality behind the hype, but preparation is needed.
Does your company have “good informatics”?
Here are the sorts of things that lead me to judge the state of informatics at a company.4 This would apply to oil and gas, based on my experience, but I’m pretty confident that these patterns show up in many technical industry contexts.
1/7: Are key signals (like operational metering) integrated into downstream reporting (good!), or do they only appear in a web-app dashboard that three people look at, manually exported, reshaped and sent downstream in spreadsheets or similar (bad!)5.
2/7: Are the non-negotiable reporting lines (to regulators, joint venture partners, key stakeholders) managed in spreadsheets (bad!) or is there a database set up to store the key records and the reporting logic that those data consumers demand (good!)6.
3/7: Is there a system-of-record that brings together data streams into a single, queriable place (good!), or is data scattered across multiple SaaS offerings, with only manual data handling to integrate between them (bad!).
4/7: Is SharePoint, or a network drive, featuring a deeply nested folder structure that requires drilling down to the centre of the earth to find some work a consultant performed 2 months ago, the primary means of sharing numerical information (bad!), or are technical teams interfacing with a database to get those figures (good!).
5/7: Are reports being sent as spreadsheets, PowerPoints, or screenshots of spreadsheets or PowerPoints to upper management (bad!), or is there a Business Intelligence solution in place that managers visit to get the information they need (good!).
6/7: Is the GIS team drowning in versioned shape files (bad!) or do they have a GIS database in place that they read and write from (good!).
7/7: Does anyone in your organisation, when hearing the term “tidy data” respond with a knowing smile (good!), or do they stare blankly/fall asleep/run away (bad!).
If you scored less than 7/7 on this quiz, call the local informatics specialist, you need some help!7
Closing thoughts
I’m obviously taking a punt, starting a company. But all I am really doing is bringing all the skills and experience I’ve acquired into a repeatable execution pattern, one that I think many companies could really benefit from.
There are too many skill sets, too many knowledge silos. The coordination problem of doing informatics right is seriously challenging. But, I think I’m well positioned to do it…
After all, I made up the term.
I’m an expert in a field of one.
Footnotes
and maybe the weather, if I forgot my hat.↩︎
council approvals might also be a challenge.↩︎
I thought I was the craziest sand guy… but there are levels to this game.↩︎
Let’s ignore the fact that nobody knows what the hell I’m talking about when I say “informatics” and pretend I’m just speaking like a well-adjusted, sane person.↩︎
… There’s only one. It’s me. Call me.↩︎