flowchart LR
F[You] --> A
A[Documents]
A --> C([Agent])
F <--> C
C --> D([Typst])
D --> E([PDF])
E --> F
A big thank you to Chris and Ant from Zai Node for providing API access to their Australian hosted, private GPU cluster for this project.
Taking the AI Pill
I spent last year in denial.
I also spent last year with a job… and maybe not having one partially explains the last 2 months. It is a wild time to be experimenting, without a boss to answer to, or an office to shuffle to each morning.
I was using LLMs every day, like most of us are, but I was always in tight control of the code I was producing, holding strong to the notion that, because I knew my work better than the stochastic parrot, I needed to keep my hands firmly on the wheel at all times. I also didn’t really use it for anything other than coding help.
And when working with clients my hands are still on the wheel, if not hovering just above it. These things can do a lot of damage very quickly. I’m sure we’re in for many disasters related to people letting the vibes take control at work. It is already starting to happen.
It would be unwise to let coding agents loose without significant guardrails and environment separation in projects managing sensitive systems…
In my own time, though?
Many are in denial about what is happening, like I was last year, but my recent experience with AI agents has made it clear to me that software development has fundamentally changed, and most other knowledge work will probably follow in the next few years.
I’m not an outlier and none of this is intended as a boast, because I don’t think any of what I’m doing is particularly impressive, but it is what becomes achievable when you put the keyboard down and open your mind to the army of digital gremlins you can now summon to do your bidding.
The gremlins have gotten smart, and maybe more importantly, very good at following instructions.
In the last two months, since deciding to really push myself with AI, I have
Built an agent orchestration “code factory” called Ponder, inspired by the work of Geoffrey Huntley and Steve Yegge. First in Python (it was early) and then in Go (when I realised I should use a better tool, and my inability to code in it didn’t matter). I’ll explain Ponder a bit more later in this post.
Built a statistics library for reuse across all my company probabilistic modelling projects, with all the JSON serialization capabilities I’ve caught myself rebuilding over and over the past few years. It treats distributions and stochastic processes as primitives that can be composed into arbitrary Monte Carlo models, all serializable to JSON for database storage, and all lightning fast to simulate using
numpyandXarrayBuilt most of an end-to-end mine site scoping/early feasibility study tool, which is essentially a hard rock version of the Resgo tool that does this kind of analysis for oil and gas prospecting. Both are now built on top of the statistics library (a major refactor for Resgo)
Written a fairly comprehensive legal analysis on a Strata dispute I’m in the middle of, with references to relevant statutes and case law, packaged up into several professionally typefaced documents intended for various recipients.
Set up a personal assistant with access to my emails and a knowledge graph via Obsidian (though to be fair, I’ve barely used it)
Made significant refactors across several company projects
Created landing page websites for the company and its products
Perhaps most surprisingly for me, I have also
- Updated my resume
Most recently, while experimenting with open-source LLMs, I’ve built a language learner’s reading aide called Lex.
Lex
Lex solves a problem I have. I love reading in Spanish, but it is really hard.
Reading in your target language is a great way to learn but it can be frustrating. You are often caught in a trade-off between comprehension and enjoyment. You don’t want to read children’s books; you want to read the things you’d enjoy in your native language, but that is usually pretty advanced. Often you’ll miss context or subtext, through an inability to comprehend at a high enough level. Poetic language is especially difficult. This makes it harder to appreciate what you are reading, and that makes it feel like a waste of good material.
Lex is the tool I’ve always wanted to help me read more difficult books, while keeping them comprehensible and enjoyable. It is heavily inspired by LingQ, which I’ve used a lot in the past, but designed to work locally with my eBook collection, with LLM assistance built in, and keyboard shortcuts customized to my exact tastes.
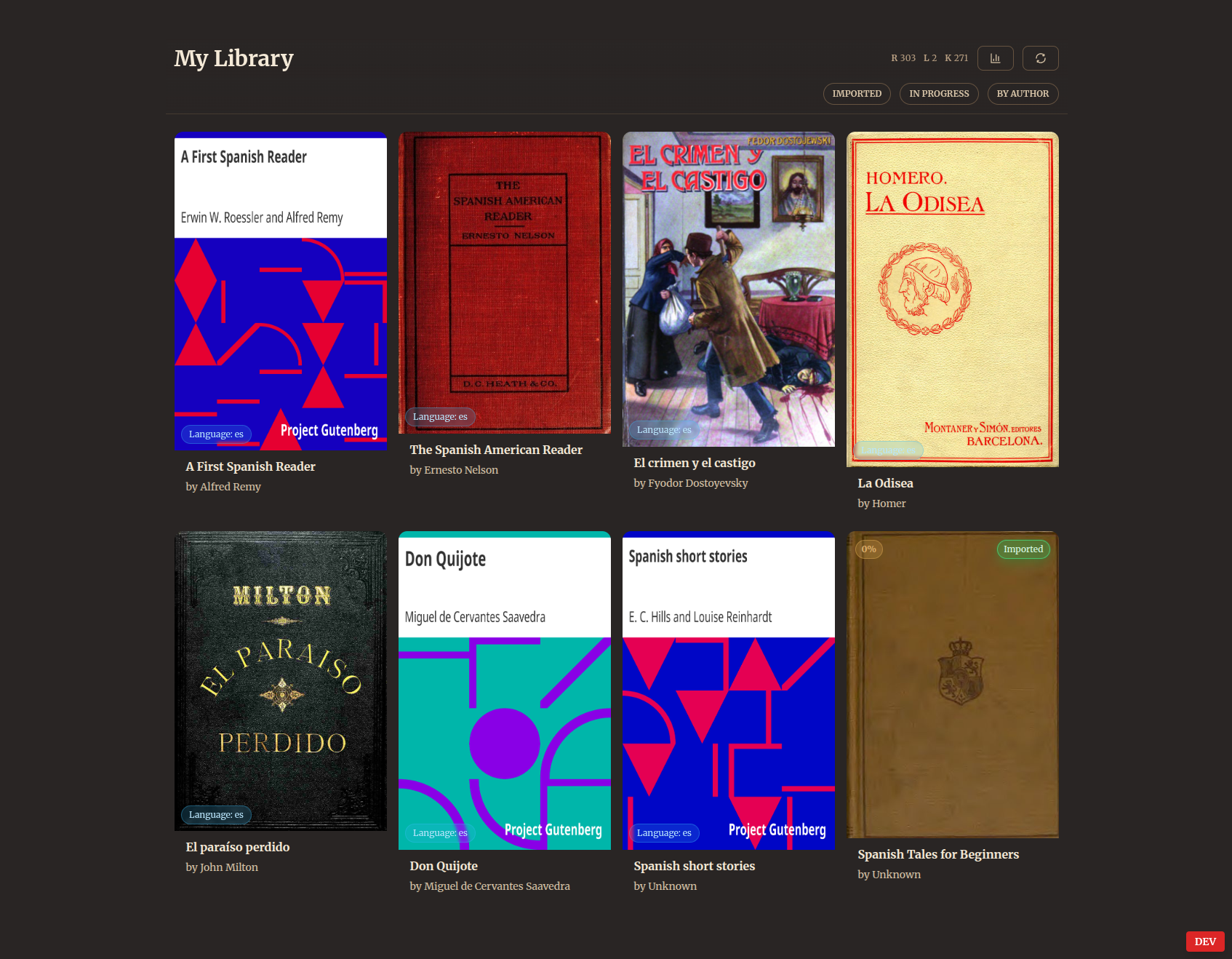
It runs as a web app on my home server, which other devices like my phone or laptop can access via my Tailscale setup. It connects to my eBook library (using an open-source program called Calibre), allowing quick imports into the database. The database tracks all the book content, as well as detailed statistics of the words I read, whether I know them or am still learning them, how many times I’ve seen them and so on.
It uses a Python based natural language processing pipeline to ingest content into the database so that it can be organized by sentence and lexeme (the abstract unit of meaning that words point to, like [“running”, “ran”, “runs”] = “run”) to make language learning progress more meaningful. Hence, “Lex”.
The Vim inspired keyboard shortcuts are:
jandkmove up and down sentences,wandbmove forward and backward through words,- upper case
WandBskip straight to highlighted words, and spacetriggers LLM help on the current word
For me at least, it is a very nice experience.
Everything is timestamped, so detailed time-series analytics can be generated:
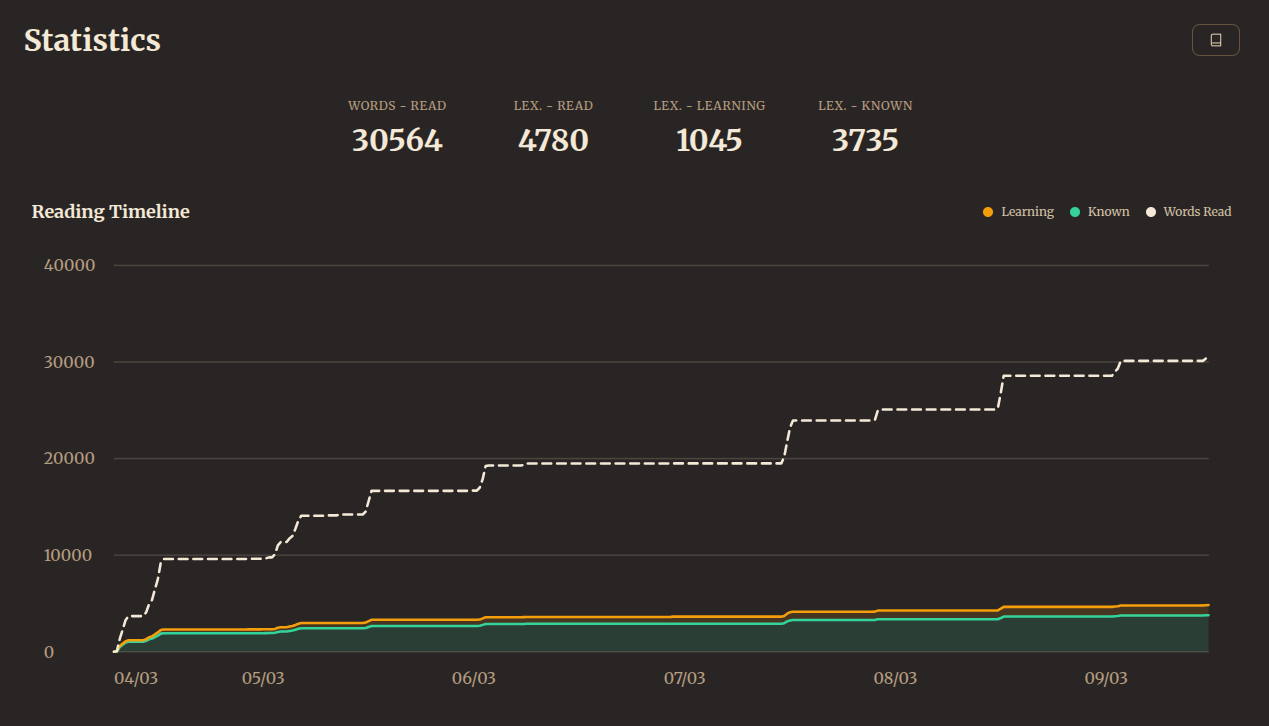
The reading statistics are a nice motivating factor for a data nerd like me, and I’m finding myself in a bit of an addictive loop, keeping my learned words increasing with reading sessions each day. The white dashed line is total words read, while the green and yellow areas are tracking lexemes that I know or am currently learning, respectively. Line go up. Feels good. Do it more.
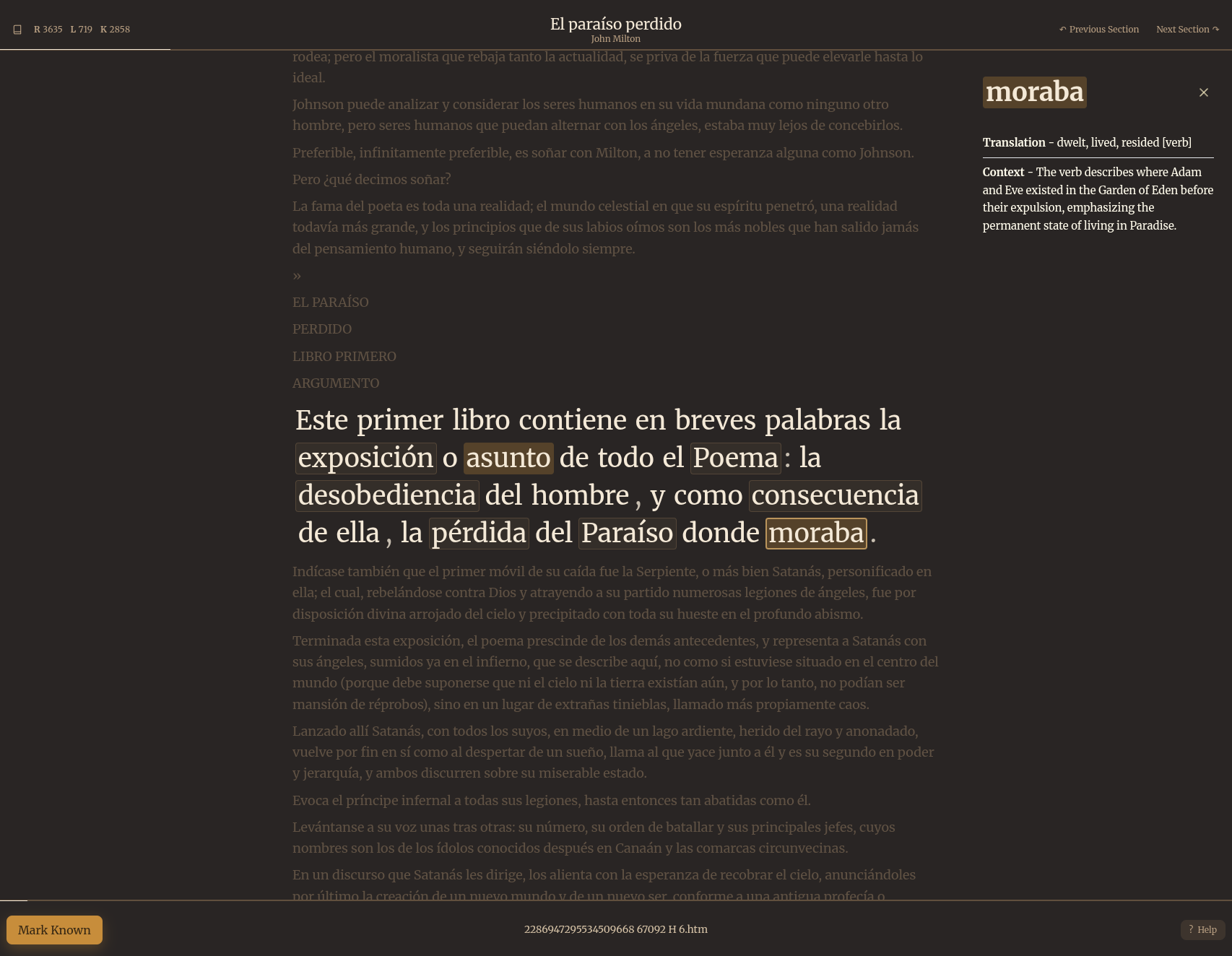
The use of a Large Language Model for translation assistance is a very natural fit. Instead of dictionary definitions (which are slow, can be misleading, and lack all context), words are explained in the context of the sentence you are reading and the book it is from. That means, even in very tricky passages using odd turns of phrase, slang, or poetric imagery, the LLM will give you a pretty good idea of what is happening. Instead of storing dictionary definitions, the database stores the explanations you get when you ask for help, so you can look through all the different contexts you have encountered words and how the model explained them.
I’ve experimented with a few different LLMs for the translation help, and have settled on Claude Haiku because it is so fast and essentially free to run (I’ve spent about 25 cents so far). Open Source models running on your own machine will soon be the best solution for these kind of applications, as they’ll remove the network hop required to call external model APIs, though I found the latest Qwen 3.5 range of models to be either reliable but too slow, or fast but too unreliable. At least for now, Haiku gave me the best mix of speed and reliability.
Everything feels very snappy and responsive, and the low contrast theme combined with big text makes long reading sessions comfortable.
There is more I can do, like improve support for other languages (wiring up additional NLP model pipelines), or adding support for Spaced Repetition style learning sessions, but for me, right now, Lex does what I need it to.
| Language | Files | Blank Lines | Comment Lines | Code Lines |
|---|---|---|---|---|
| Elixir | 89 | 3,384 | 1,802 | 13,728 |
| Python | 7 | 159 | 126 | 551 |
| JavaScript | 4 | 40 | 5 | 223 |
| Total | 100 | 3,583 | 1,933 | 14,502 |
Around 15 thousand lines of code, and I started on the 27th of February, less than two weeks ago.
I didn’t write a single line of it.
Developing Software with Agents
I decided to use Lex as an experiment, building with open-source models almost exclusively. I’ve been getting the impression that with good enough “context engineering”, open-source tokens can be just as useful as the boutique Anthropic/OpenAI ones, and the gap in capability between them is closing.
Some friends of mine at the Australian AI startup Zai Node were kind enough to provide an API key for use on this project, as they share a lot of my optimism about local and open-source LLM adoption. The majority of the project was built using Kimi K2.5 via their privately hosted API, running on their GPU cluster. This meant very low latency, very fast LLM inference.
I intentionally built Lex using tech I had no prior experience with (Elixir and Phoenix LiveView) to force myself to rely heavily on the agents to implement everything, and I never touched the code myself. The majority of the development was done using my task manager Ponder. On a few occasions I created a large backlog of tasks and just let it run overnight, waking up to thousands of new lines of tested, functional code.
I went to see Bad Bunny in Sydney while LLM agents grinded away on my codebase just as tirelessly as the concert goers, once the reggaeton started.
It took about 4 days worth of coding sessions and I had most of the application written, the rest was refinement over the next week. There were also a few subtle but important bugs that were not picked up in tests, which I only noticed digging around in the database.
Fair warning: LLM code output is all very “plausible” looking, which makes it very difficult to find mistakes if they are not captured in tests. The agent will write a test based on a mistaken assumption (maybe due to a poorly specified description of the task), which bakes in the incorrect logic. Good luck finding it.
Regardless, this would have been a month of work if I was an Elixir developer on day one, and more like 3 months learning the ropes without that prior experience. The product as written by me would also have had worse test coverage and documentation… Just being honest.
At least I would have had mastery over the codebase if I wrote it myself… I had the agents create architecture diagrams for me to help understand what was built, but honestly? I’ll never reach the level of familiarity that emerges as you write the code, and I don’t think that experience is replaceable.
Maybe I’ll build up understanding over time, but when I encounter a bug there is no alarm in my head saying “that might be because of X function in this file, check there first”, it’s usually more like “clanker pls help my buton is not wokring, fix it”. Even the database layer, that I normally take so much pride in, is obscure to me, written using Elixir’s ORM “Ecto” instead of my native SQL.
But it works!
I’m using it a lot and having a great time. It is software built just for me that I never would have bothered building otherwise. Maybe others will stumble upon it and find it useful, but that wasn’t my goal. I just wanted the thing and now I have it.
AI!
And I did it almost entirely using open-source models, for free in my case, but otherwise very cheap from other providers, using an open-source agent harness. The technology is ready, already, and it’s basically free.
Open Source AI!
Progress could grind to a halt tomorrow and things would still be irreversibly different to how they were a year ago. Regardless of the tiresome levels of hype, this is a big deal.
Ponder
I mentioned earlier that I was able to let the agents run semi-unsupervised for most of the development of Lex using my agent task manager, Ponder. So, what is it?

Ponder is fairly simple in concept. Tasks (the orbs being pondered) are narrowly scoped units of work. They are stored in a SQLite database in a Directed Acyclic Graph (DAG). Tasks have dependencies, and are only flagged as “available” if all dependencies are completed. This means that running multiple agents at once becomes fairly simple, as agents only pick up available tasks, which are unlikely to clash given the dependency graph separating them.
Each worker follows a tight completion loop:
- implement the task spec,
- write tests,
- iterate until the test suite passes,
- commit the changes, then stop.
That loop repeats across the graph as dependencies are resolved. These validation checkpoints are what make the process reliable. Without them, models will often drift and introduce bugs. Less capable models need tighter verification loops. Every LLM call is a random walk through token town… the tighter the loop, the less divergent results will be.
I found I didn’t need git worktrees (a way of isolating the working environment for each agent) - it was rare that the agents had any issues working on the codebase in parallel. I would guess worktrees, or some other creative solution would be necessary north of 10 agents running in parallel, but it would depend on the size of the codebase and the testing framework. I can’t see myself needing to go much faster, either. Working like this is already exhausting enough.
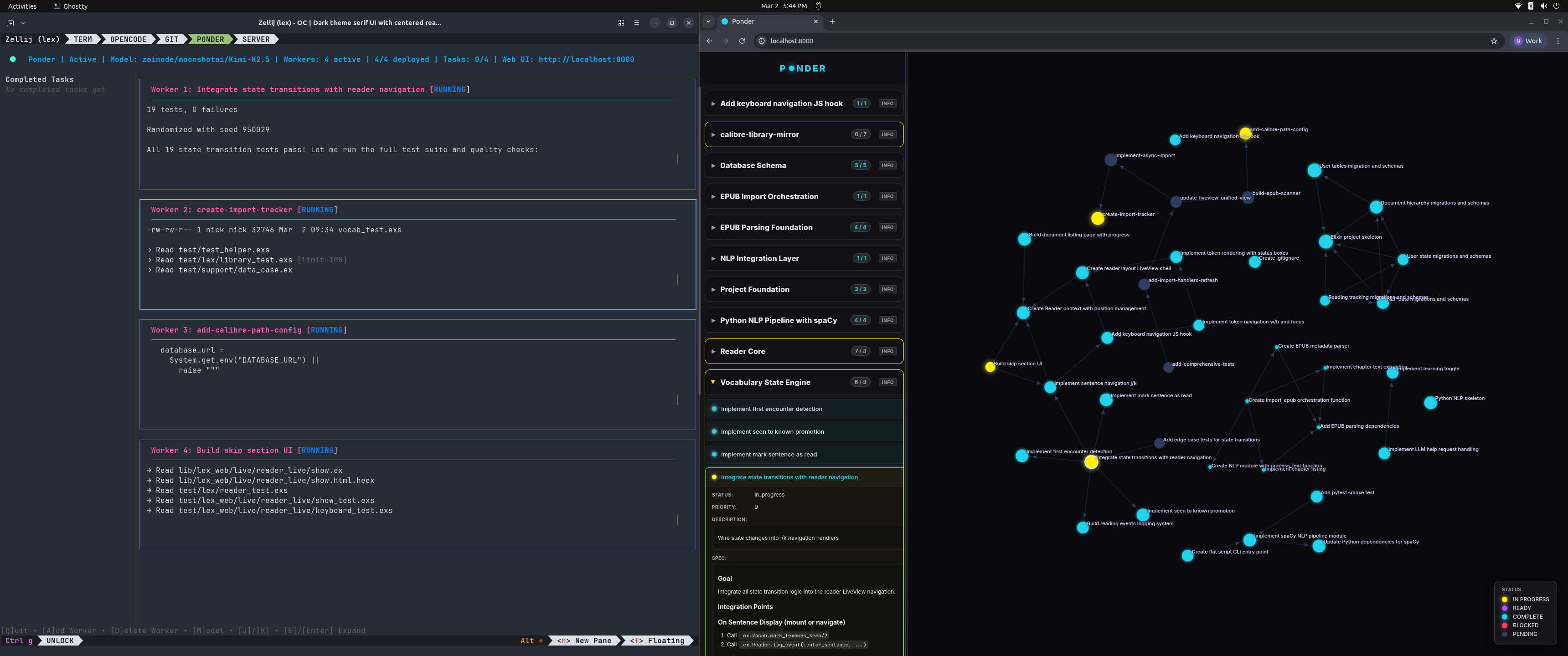
The tasks themselves are added to the graph by an orchestrator agent (the “Orbitor”) that I talk to in OpenCode, a popular open-source agentic coding tool. Tasks are highly detailed specification documents. The Orbitor is instructed to interview me, grilling me for detail before committing to a plan. This might mean 15-20 technical questions before it is satisfied.
At times I needed help to even understand what was being asked, being totally unfamiliar with Elixir and its conventions, but that is a part of the process. Despite the agents actually writing the code, there are many decisions to be made, and trade-offs to consider…

Once satisfied, the Orbitor commits the series of tasks into the graph, along with the dependencies between them. Worker assignment then happens automatically. While they write the code, I work with the Orbitor to define the next series of tasks.
Notice I’m not talking about “prompt engineering” like there is a special way of asking for things that unlocks AI’s secret potential. This is all conversational. The agent diligently writes out the detail better than I can, summarizing the key points of the interaction into the task spec and passing it to a worker.
This works stupidly well (Ponder mostly built itself using it), but is mentally exhausting. Decision fatigue builds up very quickly. That fatigue used to be mediated by stretches of relatively meditative coding, but now that is gone, and the next decision is minutes, not hours, away.
I’m not sure if other developers share this experience, but I’m often exhausted after a few days working like this. Because it is so easy to get started on new projects I’ll often have 4 or 5 experiments in progress at any given time. It’s a lot to think about, and getting lost in distracting rabbit holes is a real risk.
The most effective adopters of this technology will be those who can manage all the context switching and prudent decision making for longer stretches of time before burning out. The overlap of this quality with a clear vision of what to build (whether in a single person or a group of people), will create new companies that move mountains with this stuff.
As an aside, building Lex (or… watching it happen, at least) has taught me that Elixir is a great choice for agent orchestration projects like Ponder, and I would have chosen it if I had known better. The Erlang BEAM virtual machine that Elixir is built on top of is a perfect match for long running, concurrent and fault tolerant agent orchestration. Worker agents would be deployed with a GenServer, supervised by higher order processes (DynamicSupervisor) that spin them back up if they crash or get stuck. They’re literally called Supervisors in the language!

I would bet some big frameworks are released using Elixir. I saw that OpenAI is building with it while writing this.
Tackling an enterprise grade agent orchestration framework for managing tasks and knowledge sharing, using ideas from Ponder and my experience creating Lex, is a likely next target for our work at LD Informatics.
Some Closing Thoughts
AI is moving fast, and I imagine it is as disorienting to others as it has been to me, to the extent that often it is easier to just… look away. What I’m telling people close to me is that, while I don’t know what will happen or when, if you spend a lot of work time at a computer, you should start getting familiar and capable with AI tools.
Don’t look away.
Most people have a bad taste in their mouth from all the AI garbage being shoved into it day after day. All our feeds are full of AI generated slop. Infuriatingly cliched writing, reply bots, synthetic video clips that range from pointless to politically destabilizing, music stripped of its human soul… It all feels like a colossally disappointing waste of time and money, and in service of what end? Replacing us? I despise this stuff.
The technology feels different, though, when you ride out and confront it on your terms, and hold on to a feeling of authorship, ownership, and agency while working with it.
Yes, we’re probably in a bubble. Yes, there is a great deal of hype fueled nonsense. Yes, most AI chat buttons shoehorned into otherwise functional apps are annoying and best left ignored.
But I’m not selling you anything, and I am telling you, deadset, that this technology is real, it can do real work, and it will do it faster and cheaper than any human can. If you give it the information and clear instructions it needs, it might just do your work better than you can.
Regardless of how this feels, I think it is true, and it is better to adapt than to ignore it. People with AI proficiency will become very valuable in many industries.
And I should be clear. Completing tasks is not the same as a human doing a job. A job is not a sequence of tasks. AI Agents have a long way to go to becoming “agents” in a real sense, that can be relied on to do autonomous work over long time horizons. Ironically, they have no agency. They can’t learn. They make things up. They go completely off the rails. They’re advanced pattern matchers in a loop that can use tools to do work. That’s it. These facts diminish them, but don’t fool yourself into thinking they are useless. They are incredibly useful.
So, don’t ask for something vague and smugly watch the model fail to read your mind. That is your ego preventing you from confronting it. Don’t dismiss all its output as slop, either. That is a thought terminating cliche inviting you to stay ignorant. Give it a real, honest go, and then decide what you think based on direct experience.
If you are in the legal profession, or work in any role that requires a lot of reporting, install a coding agent and Typst (or ask the agent to install it for you), and give it the information it needs to work. Don’t rely on its model training, because it will hallucinate. Provide the documents so that it can read sources directly. When you see the perfectly templated PDF magically recompile after every change the agent makes, and you find yourself in what is essentially a live interview with the document and all its supporting materials, you will realise the way you work has fundamentally changed.
If you live in spreadsheets, install a coding agent, output your data to csv, explain the analysis you would run in Excel, and watch it recreate it with a short Python script. Now ask for all the plots and summary tables you want. Use Typst, compile it to a beautiful PDF. You don’t need to stare at a white grid of data 8 hours a day anymore. Beautiful, intuitive visualizations are how humans should interface with data, not tables of numbers. Tables of numbers are for the machines. You don’t need a understand a line of code to start doing this right now.
flowchart LR
F[You] --> A
A([Data])
A --> C[Agent]
F <--> C
C --> D([Typst])
C --> G([Python])
G --> H([Plots])
H --> D
D --> E([PDF])
E --> F
OpenCode usually has models provided for free, so you don’t even have to pay to get started. You are a single command in your computer’s terminal away from trying it:
curl -fsSL https://opencode.ai/install | bashIf you’re a software developer then you are probably riding this wave already. If not - if you are a tinkerer who enjoys solving puzzles in the peaceful solitude of programming, and you resent the robot doing it for you - try to shift your mental gears into a higher order of puzzle solving. I do miss coding by hand, I’ve been obsessed with it for years, but there is a lot of new fun to be had building with agents, as well.
Maybe you won’t be deliberating over individual function implementations, or objects and how they are wired together, but you will definitely be wrestling with software architecture, the technologies to use and the trade-offs between them. The grand vision you have for projects, the thing that motivates you to build them at all, will mean they will still feel like they are yours even if you didn’t write every line of the code.
Most would benefit from experimenting with AI, regardless of how the next few years look. That is my advice, for what it is worth.
Thanks again to Zai Node for access to their API.
And thanks for reading!